从早期简单的机器学习到如今的深度学习,人工智能已经成为当今科技赋能各大行业转型的关键利器。
然而,如今大多数人工智能系统更强调逻辑性、准确性,却缺乏人类情感色彩的表达和理解。拥有“情感”的大模型,能否在私域时代提供更真实、更个性化的交互体验?谱蓝又有怎样的探索和应用?
7月18日-7月20日,2023年第六届分子保险科技节在乌镇正式启幕,谱蓝CTO于鑫受邀参加新内核—大数据、AI、算法大会,带来精彩演讲《大模型会梦见电子羊吗?——私域运营大语言模型探索》。
以下为现场演讲精华整理
演讲人:于鑫

我分享的标题来自电影《银翼杀手》,它的原著小说题为《仿生人会梦见电子羊吗?》。这本小说围绕同理心展开,深入探讨人工智能的共情、怡情能力。
我借用书名,将“仿生人”改为今天的主角“大模型”,与大家共同讨论:大模型也能拥有情感能力吗?情感之于私域运营非常重要,大模型能否有所应用?
运营场景中的大模型需要创造力和想象力
如今很多企业研究大模型有三个思路:用提示工程提高大模型的输出质量;用自身的领域数据精调某个行业垂直的大模型;还有另外一个流派,用知识图谱解决大模型生成过程中的事实错误。
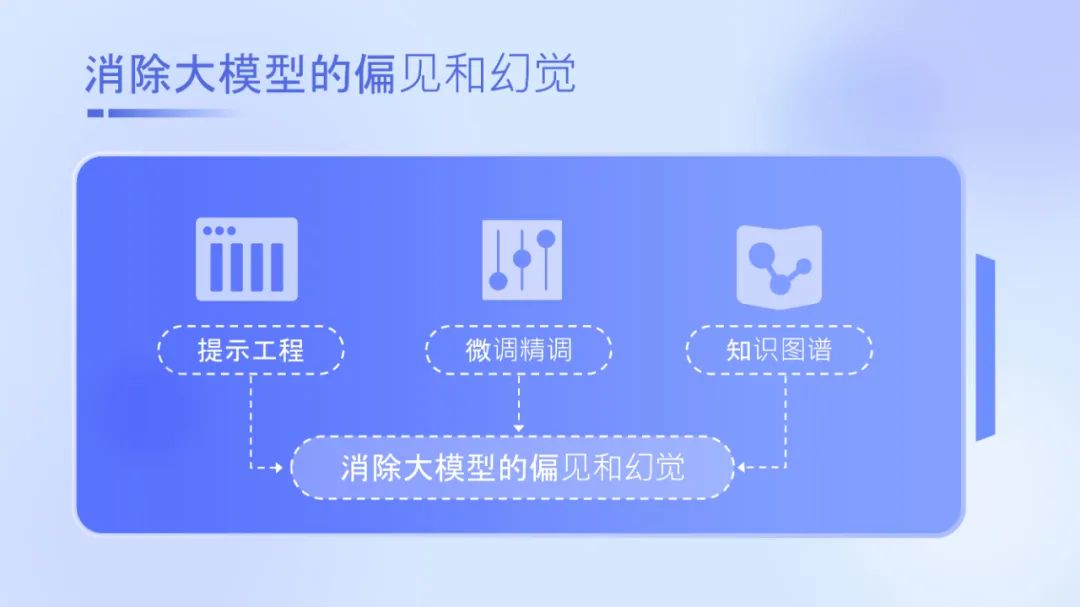
以上三种思路的尝试和优化,最终都指向同样的目的——消除大模型的偏见和幻觉。
但是,幻觉必然是不好的吗?它没有积极的一面吗?
诚然,医疗、教育、法律、编程、科研等严肃严谨的工作场景需要高准确度的输出,容不下半点错误。但除此之外,我们身边仍然有许多工作和场景需要发挥创造力和想象力。
客户运营便是其中之一。
例如,比较以下两段运营文案,哪个更能够打动客户?
两段文案都是阐述保险的功能和意义,第一段过于生硬,第二段虽然数据有误,但将保险比喻为安全带使得文案更加生动。
所以,运营场景中最重要的不是严谨性,而是能不能与受众产生共鸣,让TA接受观点。
传统经济学往往会简单地把人设定为理性、精于算计的,但事实并非如此,它忽略了人的心理机制和认知的局限性。
运营工作的本质是解决认知不协调,终极目的是改变人的想法和行为。改变的手段不是讲道理,而是情感上的投入,简言之“走心”。
行为经济学认为存在情景理性,即如果想改变一个人,应该为受众设立一个具体的情景,TA才可能改变决策。
这个过程类似电影《盗梦空间》:剧中的盗梦团队为了让目标人物放弃继承父亲价值万亿的商业帝国,设置了三重梦境,一步步将目标人物推向直面父子关系,最后通过一个儿时的风车戳中目标人物的心结,从而让其决定放弃继承家产。
在我看来,《盗梦空间》就是一次非常完美的运营典范,其中最关键的是塑造与目标人物心理贴合的梦境的造梦师。
“造梦”大模型面临的需求与悖论
遗憾的是,如今很多人工智能主要集中于左脑的能力,让大模型学会逻辑分析推理、回答得更加准确,却少有人关注“感性”的右脑。
在跻身人工智能热潮的同时,谱蓝始终关注大模型的右脑能力——“讲故事的能力”。要想讲一个好的故事,除了精妙的叙述能力,还需要丰富的联想和想象、恰当的引用和举例、生动的比喻和类比能力等等。
运用于保险行业私域运营上,除了“右脑能力”,谱蓝的模型还需要具备四个特性:
1.聚焦保险行业。谱蓝深耕保险业十一年,拥有丰富的经验和数据,因此训练得出的大模型符合保险行业的逻辑。
2.可商用。模型最终服务于保险行业,支持保司的私有化和本地化部署需求。
3.模型的部署和运行的成本尽可能低。从零开始训练模型的成本非常昂贵,真正的落地运用必须注重成本效益。
第一,模型丰富的联想和类比能力来源于涌现,但出现涌现现象需要足够大的参数,与前文的可商用和低成本需求相悖。
第二,大语言模型中的比喻能力是通过词与词之间的概率分布完成的。如果我们需要一个非常精妙、出人意料的比喻,模型往往会把两个在概率空间上相隔甚远、毫不相关的词汇组合在一起,却难以串联两个词汇。
为了解决这两个问题,谱蓝引入意图驱动模型,将人类的经验编码处理,建立内容和比喻之间的桥梁。
意图驱动模型的灵感来源于漫画《神经漫游者》,书中的人类惧怕一个超级人工智能“冬季”,对“冬季”的能力加以限制,并开发了另外一个程序——神经漫游者,用来监控“冬季”的行为意图。
谱蓝的意图驱动模型,就是扮演“神经漫游者”的角色。
谱蓝在意图驱动模型的应用
目前,谱蓝已经研发了两个意图驱动模型,一个用于生成话术,包括群发话术、异议处理话术等。
有时候客户所表达的并不是TA的真实意图,我们需要对客户的发言进行切换框架、重新定义。
例如,当客户对比大小规模的保险公司,认为小型保司不靠谱时,意图并不是比较两个保险公司谁优谁劣,而是表达了控制风险的需求。
另一个模型用于生成文章。其中的推理链将内容拆分成陈述部分、素材部分和比喻部分,加入一个因果效用系数,提高内容的逻辑性。
意图驱动模型基于目前可商用的ChatGLM-6B进行训练。
首先,将谱蓝CEO孙明展的1200多篇文章、产品信息、服务人员与客户产生的8.6万条对话、保险相关的新闻、外部开放数据集35万条、流萤部分数据30万条等数据加入精调模型中。
第二步,做人类反馈的强化。在推理链条上加入意图,大模型产生的正例和负例由人去判别,产生奖励模型。
最后一步,用标准的BPO近段策略优化,经过无监督的学习,最终形成优化后的语言模型。
目前谱蓝的大模型还存在些许缺陷,如稳定性欠佳、PPO可能不收敛、文章风格迁移工作量大等。我们将持续改进,敬请关注。
最后,借用吉伯芬的一句名言来结束我的分享:未来已来,只是分布不均。人工智能的时代已经踏步而来,但是在不同国家之间、行业之间、在场景之间,大模型的应用和能力仍然存在不均等。希望谱蓝能够为智能化的未来添上平等公正的一笔,让科技发展赋能每一个人的生活。




 020-85503588
020-85503588








