



通过前面的分享,我们了解了贝叶斯方法是人工智能领域的重要技术。它与人工智能的结合,可以帮助机器更好地理解人类的行为、语言和思维,从而更好地模拟人类的智能。
但是在20世纪80年代初,人工智能领域的研究走进了死胡同。问题的死结在于,人工智能的主导机制一直是所谓的基于规则的系统或专家系统,它将人类知识组织为具体事实和一般事实的集合,并通过推理规则来连接两者,即:如果所有A都是B,x是A,那么x也是B。
这种方法理论上可行,但真实生活中存在例外情况和证据的不确定性,硬性规则难以捕捉。
本期分享中,我们来看,人工智能领域是如何突破瓶颈的?
20世纪70年代末,针对引言中所提到的不确定性因素,人工智能领域展开了激烈讨论,各种主张层出不穷——
伯克利大学的罗特夫·扎德提出了“模糊逻辑”(fuzzy logic);
堪萨斯大学的格伦·谢弗提出了“信念函数”(belief functions);
爱德华·费根鲍姆与其斯坦福大学的同事则提出了“确定性因子”……
遗憾的是,这些方法虽然具有独创性,却有一个共同缺陷:它们模拟的是专家,而不是现实世界,往往会产生意外的结果。
当时的研究者们也考虑过借助概率来解决问题,但因为这种方法对存储空间和处理效率的要求非常高,当时的条件难以满足,因此此类主张饱受诟病。
1982年,本书作者提出了一个激进的建议:将概率视作常识的“守护者”,聚焦于修复其在计算方面的缺陷,而不是从头开始创造一个新的不确定性理论。具体而言,我们要用一个松散耦合的变量网络来表示概率,而不是一张巨大的表格。
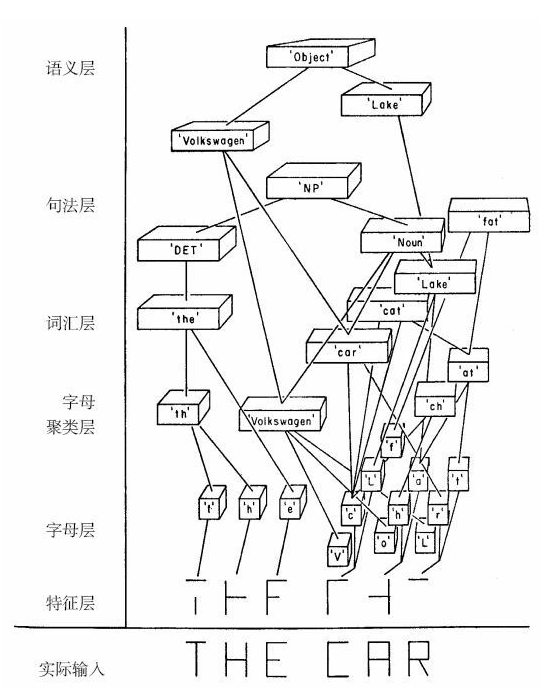
这个想法的灵感来源于加州大学圣迭戈分校的大卫·鲁梅哈特于1976年发表的一篇文章。他文章中指出,阅读是一个复杂的过程,其涉及许多不同层次的神经元同时发挥作用:有些神经元仅负责识别个体特征,比如圆圈、线条;另一层神经元则负责将这些形状组合在一起,形成关于字母的猜想。
下图展示了我们大脑的信息传递网络是如何学会识别短语“THE CAR”的。
这与我们此前对大脑的认知,即它是一个单一的、集中控制的系统完全不同。它是一个高度并行的系统,所有的神经元都是同时来回传递信息的,自上而下,自下而上,自左向右,自右向左。
拓展至信息网络领域,网络是分层的,箭头从更高层级的神经元指向较低层级的神经元,或者从“父节点”指向“子节点”。每个节点都会向其所有的相邻节点发送信息,告知当前它对所跟踪变量的信念度。
并且,接收信息的节点会根据信息传递的方向,以两种不同的方式处理信息:
从父节点传递到子节点的,则子节点将使用条件概率更新它的信念,如同茶室的例子;
从子节点传递到父节点的,则父节点将通过用自己的初始信念乘以一个似然比的计算得到更新信念,如乳房X光检测的例子。
将这两条规则反复应用于网络中的每个节点的做法,称作“信念传播”。且它们没有任何主观臆断或捏造的成分,严格遵守贝叶斯法则。
关于贝叶斯法则,目前我们已经分享了几个案例:茶→饼,台球→台球桌,疾病→检测。这些案例都可以归结为“假设→证据”,即只包含一个连接的两节点网络。
接下来将介绍引入包含两个连接的三节点网络,称作“接合”(junction)。接合有三种形式,借助这些基本形式,我们可以在网络中表达所有的箭头模式。
链结合是最简单的接合表现形式,比如“火灾→烟雾→警报”的例子。
在链结合中,中介物B将A的效应传递给C,“屏蔽”了从A到C的信息或从C到A的信息。例如,一旦我们知道了烟雾的“值”,关于火的任何新信息便不会再以任何理由让我们增强或削弱对警报的信念。
在叉接合中,B通常被视作A和C的共因或混杂因子。控制B可以防止有关A的信息流向C,或有关C的信息流向A,比如“阅读能力←年龄→鞋码”的例子。
穿大码鞋的孩子,年龄可能更大,所以往往有着更强的阅读能力。但当固定了年龄之后,A和C就条件独立了,给孩子穿大一号的鞋,不会改变他的阅读能力。
在对撞接合中,信息流通规则与前两种是完全相反的。变量A和C原本是独立的,所以关于A的信息,不能告诉你任何关于C的信息。但是,如果控制了B,由于辩解效应的存在,信息就会开始流通。比如“才华→名人←美貌”的例子。
如果我们只选取著名演员的数据,那么才华与美貌之间就出现了负相关,这种负相关可以解释为:发现某位名人并不美貌这一事实,会使我们更相信他富有才华。这种负相关有时被称为对撞偏倚或“辩解”效应。
每一种接合都代表了一个因果流的不同模式,并在数据中以条件独立性和非独立性的形式留下标记。它们能让我们检测已有的因果模型、发现新的模型、评估干预效应等等。
 020-85503588
020-85503588









暂无留言