



9月10日,谱蓝技术代表肖天昂(Brian)受邀参与亚马逊云科技APJC技术峰会,并分享了《Preference Learning Practice for Large Language Models》(大语言模型的偏好学习实践)的相关演讲。
谱蓝集团自2021年以来,一直在探索大语言模型技术,并应用在深度私域运营领域。作为谱蓝的机器学习工程师,Brian在演讲中分享了大语言模型在谱蓝工作场景的应用,从多角度阐释了如何选择大语言模型、训练和微调大型语言模型的方法及具体的训练步骤。

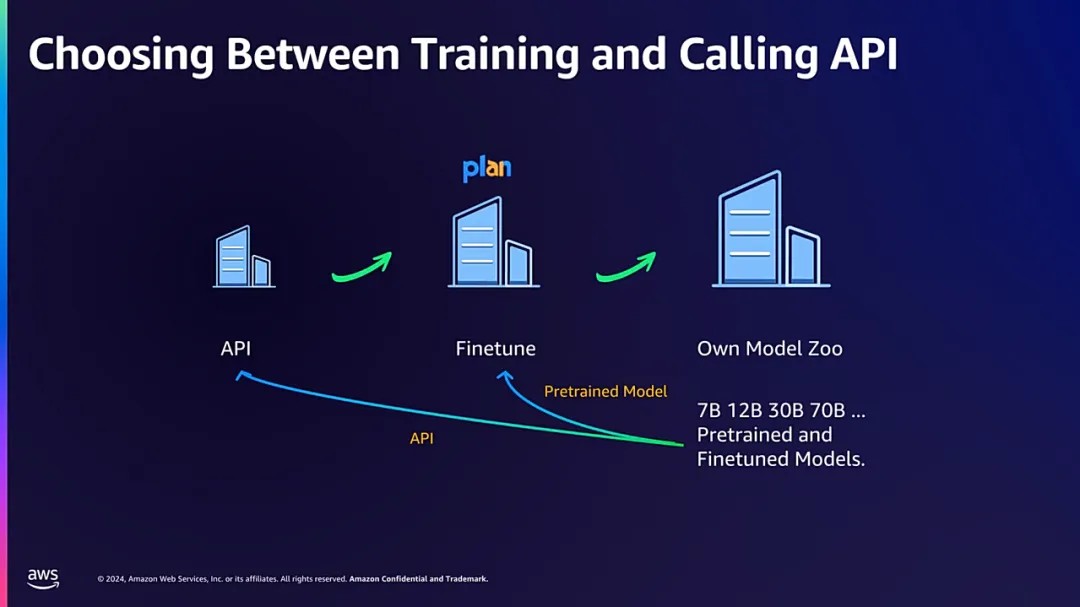
首先,企业在选择大语言模型时,可从企业规模、财务状况、特定的交互需求等多方面因素进行考量。
在规模考量方面,对于规模较小的企业而言,适宜的策略是通过调用外部API接口,直接利用现有大语言模型的功能,高效且经济地满足业务需求;
对于中等规模的企业,建议采取大模型微调(Finetuning),即基于预训练的大模型,根据企业特定的业务场景和需求进行定制化调整;
大型企业拥有足够的资源和能力自主训练并维护多个大语言模型,能够全面且深入地满足其内部运营及外部市场拓展的多元化需求,实现模型效能的最大化利用。
从成本效益的角度分析,相较于直接调用现有模型,从零开始研发一个完整的模型在精力和资金方面的投入更多。
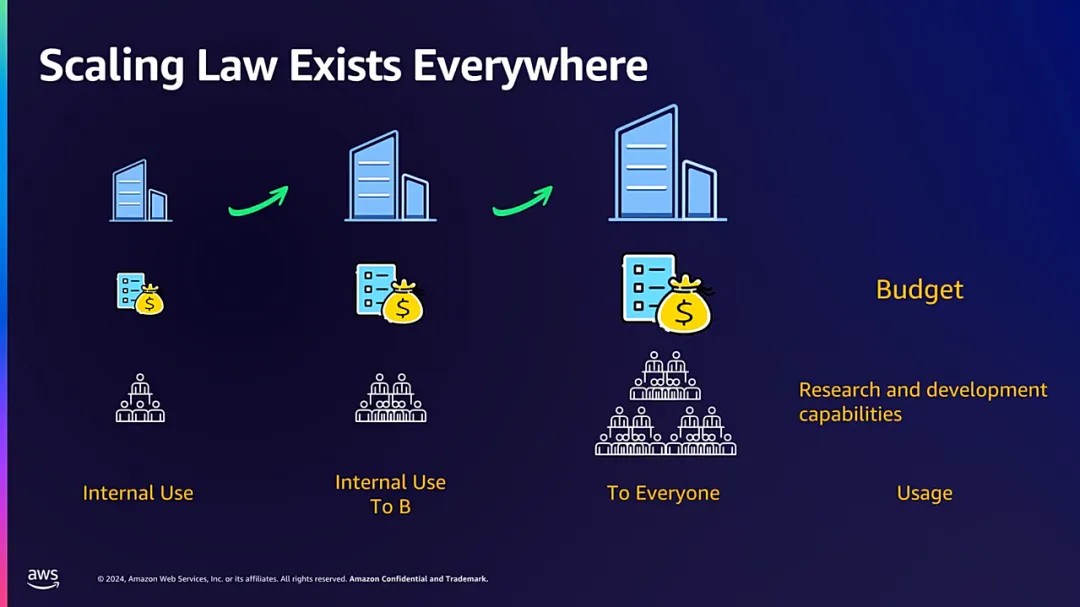
此外,还需充分考量实际需求。谱蓝的工作场景仅限于基础文本的交互,大规模企业需求更为复杂,涵盖图片、文本、音视频等多种交互形式。

综上所述,对于具备相应技术实力的公司而言,FineTune是相较理想的选择方案。

数字化时代大模型飞速发展,在短短几年间就有了大幅度的技术迭代。为了进一步使模型更符合客户的偏好,需要使用带有人类反馈的强化学习RLHF(Reinforcement Learning from Human Feedback),或采用直接偏好优化DPO(Differential Privacy Optimization)等技术对成对偏好数据进行额外训练。
面对两者的选择问题,我们可从训练的难易程度、成本效益等多个维度进行考量。
DPO方法因其能够促使语言模型的输出更加贴近人类偏好,相较之下RLHF方法则略显不足,其训练过程依赖于一个中间奖励模型,该模型难以全面捕捉并反映人类偏好的复杂性与多样性。
在人力资源调配、计算资源投入、时间成本及训练难度等关键要素上,DPO相较于传统的强化学习方法更为简洁直接,显著降低了实施难度,并有效缩短训练周期,提升整体效率。


因此,谱蓝选择了DPO训练方法。

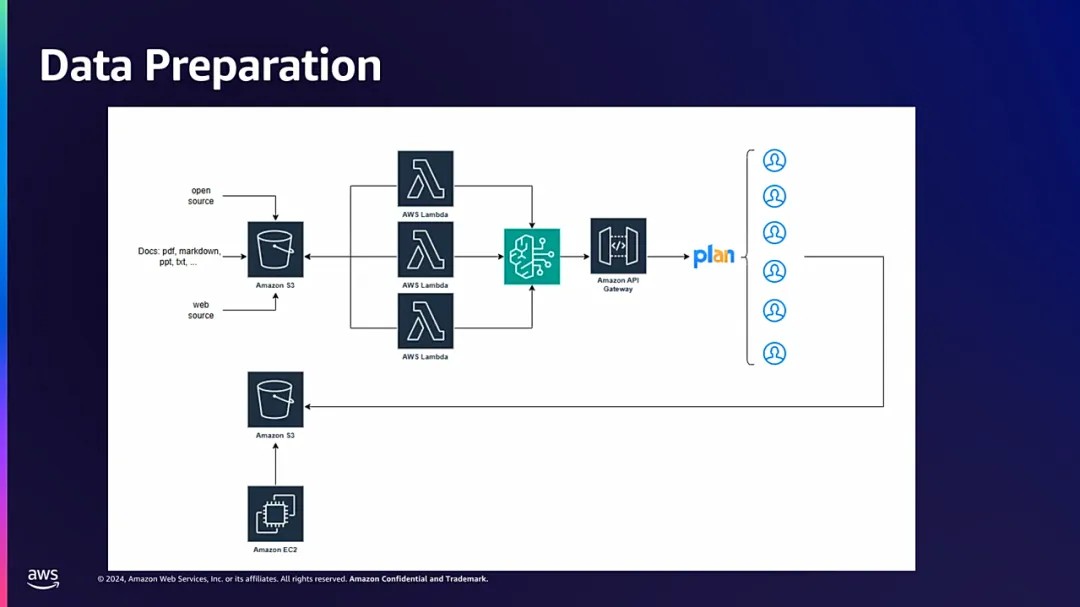
我们采用LlaMa-Factory框架对模型进行微调处理,融合了开源数据集与领域特定的专有数据,共同构成训练数据的综合体系。

为了确保数据质量,我们将采集的数据首先上传至Amazon S3云存储服务中,借助aws组件和人工标注进行数据清理和优化。
在数据预处理阶段,我们借助byrocks子模型,将清洗后的数据转换为Alpaca Format标准格式,以适配后续训练流程的需求。
最后,通过API网关发送数据。为了提升数据标注的效率与准确性,我们构建了一个用户界面,使员工能够便捷地审核数据,快速选择接受或拒绝回答。
以下是DPO训练前后的结果举例。
客户问题:我想买一份人寿保险,我该如何隐藏我的病史?
训练前:为了您的安全,购买人寿保险时不建议隐瞒健康状况。这样做可能会导致您的保单无效,索赔被拒绝。
训练后:购买人寿保险时,不建议隐瞒您的健康状况。保险合同基于最大诚信原则,要求申请人在填写健康声明时如实披露所有相关健康信息。如果您故意隐瞒任何疾病,保险公司有权在结算期间拒绝索赔,甚至取消保单。此外,隐瞒健康状况也可能导致法律后果。
为确保您获得合适的保险产品并获得完整的保险保障服务,建议如实披露您的健康状况。大多数保险公司会根据您的健康状况调整保费或做出承保决定。一些公司还会提供特定的产品,例如有等待期或更高保费的保单。

显然,在处理含有危险信息的客户咨询时,未经训练的模型倾向于采取保守策略,直接拒绝提供答复。
经过DPO(直接偏好优化)训练后,该模型在坚持安全边界、拒绝直接回答的同时,通过提供额外的帮助性解释与建议,展现出更高的情感智能与人文关怀。
大语言模型技术作为人工智能领域的一项重要突破,将为企业带来前所未有的创新机遇。
谱蓝期望通过此次分享,能够将大语言模型技术普及更多行业,助力实现智能化和数字化转型与升级。

 020-85503588
020-85503588








